
在MySQL数据库中,这4种方式可以避免重复的插入数据
在MySQL数据库中,这4种方式可以避免重复的插入数据
例如:新建了一个user测试表,主要有id,username,sex,address这4个字段,其中主键为id(自增),同时对username字段设置了唯一索引:
01 insert ignore into
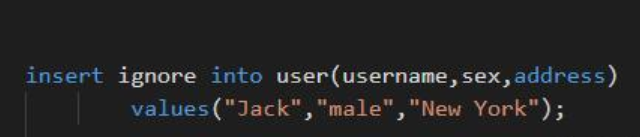
即插入数据时,如果数据存在,则忽略此次插入,前提条件是插入的数据字段设置了主键或唯一索引,测试SQL语句如下,当插入本条数据时,MySQL数据库会首先检索已有数据(也就是idx_username索引),如果存在,则忽略本次插入,如果不存在,则正常插入数据:
02 on duplicate key update 存在则更新
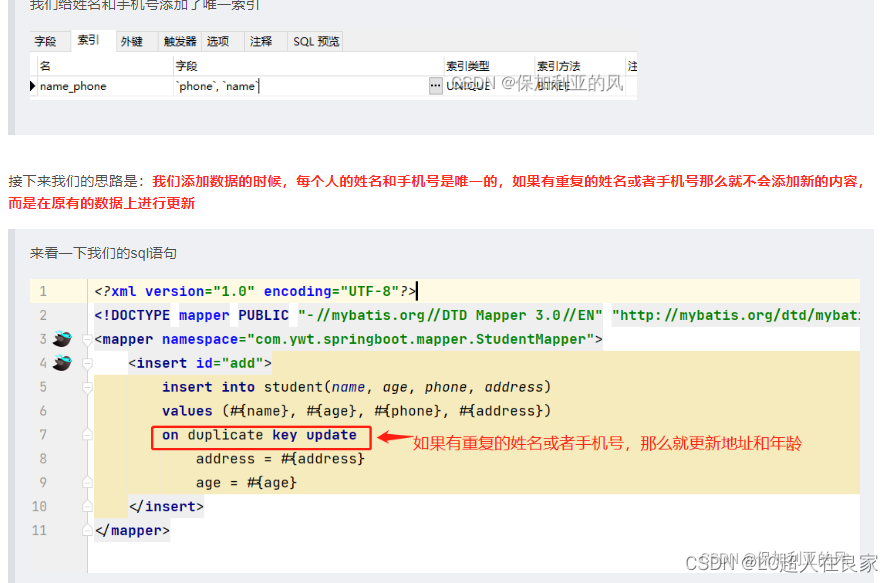
即插入数据时,如果数据存在,则执行更新操作,前提条件同上,也是插入的数据字段设置了主键或唯一索引,测试SQL语句如下,当插入本条记录时,MySQL数据库会首先检索已有数据(idx_username索引),如果存在,则执行update更新操作,如果不存在,则直接插入: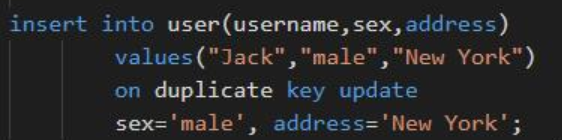
03 replace into
即插入数据时,如果数据存在,则删除再插入,前提条件同上,插入的数据字段需要设置主键或唯一索引,测试SQL语句如下,当插入本条记录时,MySQL数据库会首先检索已有数据(idx_username索引),如果存在,则先删除旧数据,然后再插入,如果不存在,则直接插入:
04 insert if not exists 存在则忽略
即insert into … select … where not exist … ,这种方式适合于插入的数据字段没有设置主键或唯一索引,当插入一条数据时,首先判断MySQL数据库中是否存在这条数据,如果不存在,则正常插入,如果存在,则忽略:
目前,就分享这4种MySQL处理重复数据的方式吧,前3种方式适合字段设置了主键或唯一索引,最后一种方式则没有此限制
上一条:MySQL事件(event)
下一条:Mysql中event事件示例




 扫一扫添加微信
扫一扫添加微信